JS获取整个页面文档的实现代码
唯一需要注意的地方:
innerText与textContent,显示页面的时候不能用innerHTML,否则会被解析。innerText与textContent是在除FF之外的浏览器与FF之间的差异。
var innerText = document.body.innerText ? 'innerText' : 'textContent';
上面的语句在开头处理以避免多次判断
demo贴图:
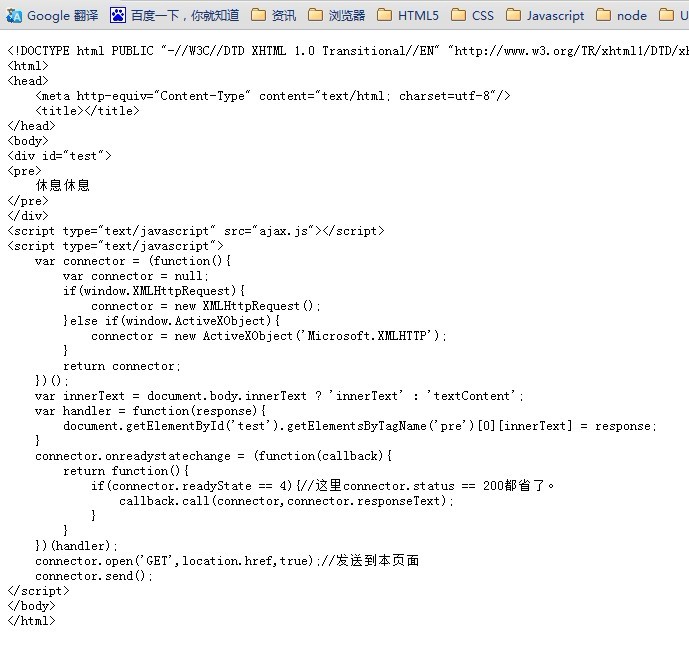
demo:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<title></title>
</head>
<body>
<div id="test">
<pre>
休息休息
</pre>
</div>
<script type="text/javascript" src="ajax.js"></script>
<script type="text/javascript">
var connector = (function(){
var connector = null;
if(window.XMLHttpRequest){
connector = new XMLHttpRequest();
}else if(window.ActiveXObject){
connector = new ActiveXObject('Microsoft.XMLHTTP');
}
return connector;
})();
var innerText = document.body.innerText ? 'innerText' : 'textContent';
var handler = function(response){
document.getElementById('test').getElementsByTagName('pre')[0][innerText] = response;
}
connector.onreadystatechange = (function(callback){
return function(){
if(connector.readyState == 4){//这里connector.status == 200都省了。
callback.call(connector,connector.responseText);
}
}
})(handler);
connector.open('GET',location.href,true);//发送到本页面
connector.send();
</script>
</body>
</html>