jQuery源码中的chunker 正则过滤符分析
这是Jq中最长的一个正则了,也研究了很久,一直很懵懂,感觉还是通过调试,然后一步一步的分析值理解起来比较容易,
我尝试做成图形比较直观一点,以不同的颜色区分了一下,如下图:
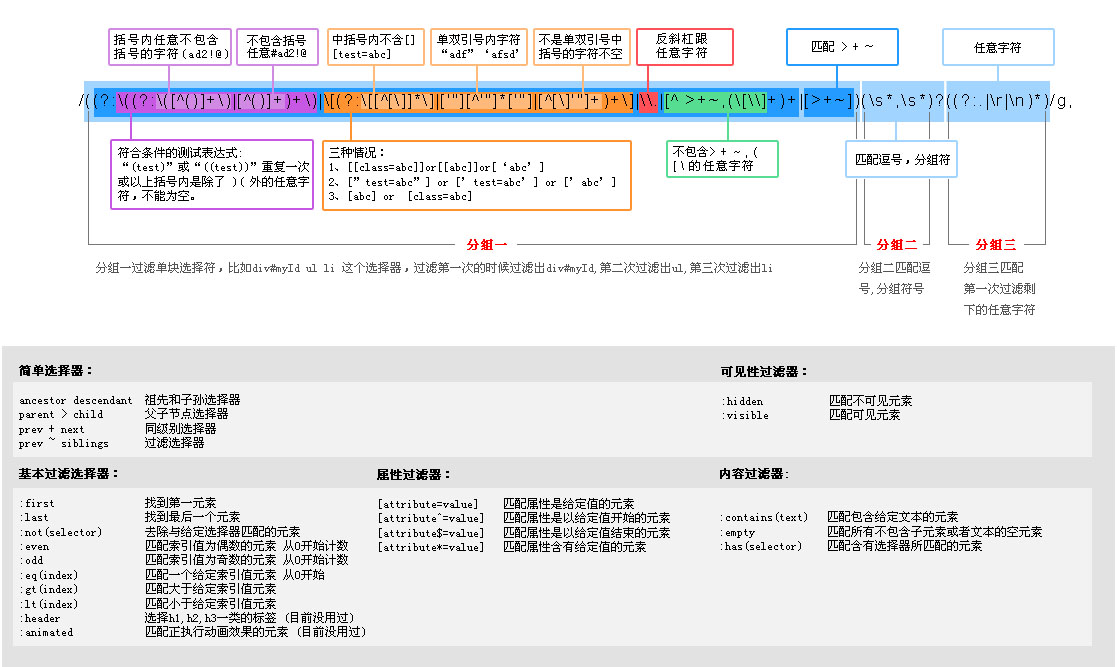
分组一是通过以下代码逐一拆分成一个数组的:
// 此处循环的作用是拆分每个选择器到 parts 数组,比如div#id>p ul li 拆分成['div#id','>','p','ul','li']
while ( (chunker.exec(""), m = chunker.exec(soFar)) !== null ) {
// soFar存储的是过滤了第一层后的选择符字符串,也就是图片上的分组三
soFar = m[3];
//选择器块第一部分推入数组
parts.push( m[1] );
// 如果拆分到了逗号的地方',',则前一组结束,跳出循环,到另外一组选择器了
if ( m[2] ) {
// 记录另外一组选择器
extra = m[3];
break;
}
}
其它的比如ID,class之类的就好理解了
match: {
// \u00c0-\uFFFF 匹配多个国家或名族的字母文字
ID: /#((?:[\w\u00c0-\uFFFF-]|\\.)+)/, //如:#myId
CLASS: /\.((?:[\w\u00c0-\uFFFF-]|\\.)+)/, // 如:.myClass
NAME: /\[name=['"]*((?:[\w\u00c0-\uFFFF-]|\\.)+)['"]*\]/, //如:[name="myName"]
ATTR: /\[\s*((?:[\w\u00c0-\uFFFF-]|\\.)+)\s*(?:(\S?=)\s*(['"]*)(.*?)\3|)\s*\]/, //如:[attribute="value"]
TAG: /^((?:[\w\u00c0-\uFFFF\*-]|\\.)+)/, //如:div p a
CHILD: /:(only|nth|last|first)-child(?:\((even|odd|[\dn+-]*)\))?/, //如::first-child or :nth-child(5n+1)
POS: /:(nth|eq|gt|lt|first|last|even|odd)(?:\((\d*)\))?(?=[^-]|$)/, //如::nth(3) span
PSEUDO: /:((?:[\w\u00c0-\uFFFF-]|\\.)+)(?:\((['"]?)((?:\([^\)]+\)|[^\(\)]*)+)\2\))?/ // :jlkj\kjl('kl(kklk)kl')
}
未完待续……